2024.09.10ヒューマン・イン・ザ・ループ:AIファーストの不正判定と加重ルールの比較
- #AI
- #アカウント不正
- #決済不正
本記事は、Sift Science, Inc.のBlog記事「https://sift.com/blog/humans-in-the-loop-ai-first-fraud-decisioning-vs-weighted-rules」を日本語に翻訳したものです。
本記事の著作権は、Sift Science, Inc.および同社の国内パートナーである株式会社スクデットに帰属します。
Coby Montoya 著/ 2024年3月20日

機械学習 (ML) は、データから知識を抽出し、自律的に学習できるAIの応用分野です。AI/ML(人工知能と機械学習)とルールは、不正検知ソリューションのディシジョン エンジン コンポーネントに含まれる判断機能です。
各不正検知ソリューションは独自の方法で意思決定を行いますが、どのソリューションにも、イベント、トランザクションのリスクを評価するディスジョンエンジンが搭載されています。
一部の企業では、加重ルールベースのディシジョンエンジンを使用しています。加重ルールは次のように機能します。
1.担当者やソリューションプロバイダーは、不正犯または正当なユーザーに関する一般的な条件をもとにルールを作成します。例えば、「新規顧客」などという条件が考えられます。
2.新規顧客であること自体はリスクではありません。ただし、「新規顧客」という条件が「既知の不正なIP」や「フラグ付きメールアドレス」などの他の設定条件と結びつくと、状況は変わります。
3.担当者は、条件にポイントという形で重み付けを行います。
4.イベントやトランザクションが評価されると、事前に設定された条件に該当するルールが適用され、ポイントが割り当てられ、その合計がリスクスコアを決定します。このスコアは、承認、チャレンジ、拒否などの判断の推奨に結びつきます。
加重ルールのメリット
- 人間によるルール設定を確認できるため、ルール条件は非常に簡単に理解できます。
- これらのシステムを利用するユーザーは、イベントやトランザクションがどのような理由でそのスコアになったのか正確に把握できます。
加重ルールの課題
- ルールは静的で、担当者がルールの条件や重み付けを手動で更新しない限り変更されません。
- ルールの最適化には非常に時間がかかることがあります。ルールは他のルールと並行して実行されるため、1つのルールがどの程度効果的か、またそのルールがトランザクションやイベントの最終結果にどの程度寄与したかを正確に把握することは困難です。
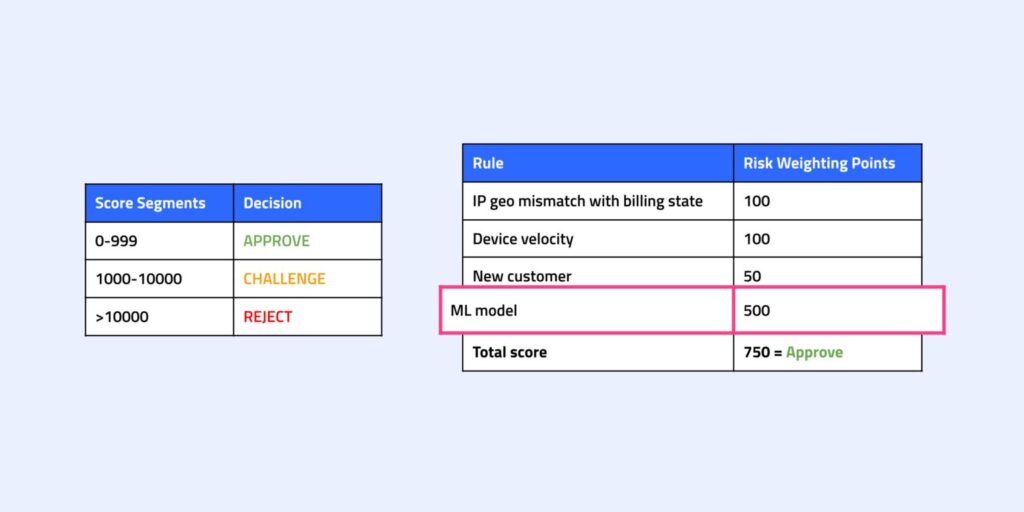
多くの企業では、加重ルールベースのディシジョンエンジンにAIコンポーネントを追加していますが、AIモデルのスコアは通常、加重ルールのスコアと組み合わされ、実質的には追加のルールとして機能します。
ルールセットが定期的に更新されない場合、AIモデルの効果が弱まる可能性があります。もう一つの課題は、ルールの重複です。たとえば、MLの「特徴」(既存の静的なルール条件と非常によく似た条件)が同じアクションや結果を複数回引き起こし、同じ条件に対して、過度のリスクが与えられることになります。これにより、マニュアルレビューが増加することがあります。
SiftのようなAIファーストのディシジョンエンジンを持つ企業は、異なるアプローチを採用しています。数百もの個別の条件を手動で処理し、それぞれに固定の重み付けを適用する代わりに、SiftのAIモデルは20,000以上の条件を含みます。また、人間による更新を必要とする静的な加重ルールフレームワークとは異なり、これらのAIモデルの特徴は、基本的なアルゴリズムに基づいて、各イベントごとに自動的かつ動的に重み付けされます。
また、Sift は、カスタムルールロジックと AIモデルロジックを分離しており、ルールスコアとAIスコアを混合することはありません。AIがスコアを計算した後に、カスタムルールロジックを適用して、そのスコアと追加条件を組み合わせたり、AIの推奨を上書きしたりすることが可能です。
AIスコアの上書きは通常は必要ではありませんが、私たちは、クライアントが自分の意思決定戦略を完全にコントロールできるようにすべきだと考えています。当社のソリューションには「Clearbox Decisioning」という機能が搭載されており、ユーザーにAIと機械学習モデルのすべてのロジック、シグナル、インサイトを完全に公開します。これにより、担当者の生産性を高め、事業目標と一致した意思決定を成長の各段階で行うことができます。この透明性はすべての業界において重要ですが、特にAIと機械学習による意思決定が収益や顧客維持に大きく影響する業界では非常に重要です。
Siftの動作を確認するには、お問合せをいただくか、 Siftの機能と利点を調べてみてください。
